Introduction
En France, chaque année, plus de 140 000 personnes sont hospitalisées à la suite d’un accident vasculaire cérébral (AVC)1. Environ un tiers de ces patients présentent une aphasie2, trouble séquellaire durable, d’intensité variable, qui affecte le langage et la communication. Cette atteinte se caractérise principalement par un déficit du lexique, avec une impossibilité ou la difficulté à produire le bon mot au bon moment. Il arrive que les mots ne viennent pas du tout (manque du mot), mais le plus souvent ils sont remplacés par d’autres mots appartenant ou non au lexique d’une langue donnée. Les orthophonistes qualifient ces transformations de paraphasies3 sémantiques, phonologiques, ou morphologiques selon le lien observé entre le mot attendu et le mot prononcé par le patient. Il est à ce jour encore difficile de déterminer clairement si ces substitutions lexicales sont imputables au déficit ou bien à une forme de compensation (voir Tran, 2018 pour une discussion sur la question de la stratégie dénominative). L’évaluation orthophonique consiste à mesurer la présence, le type et la fréquence de ces paraphasies dans les énoncés d’un patient donné (Sabadell et al., 2018), afin de mesurer la sévérité de l’atteinte, d’aider à identifier les systèmes déficitaires et cibler la poursuite de l’intervention orthophonique. Parmi les paraphasies identifiées, il semble que les déviations lexicales les plus souvent rencontrées chez les patients avec aphasie sont d’ordre phonémique (ex. tour au lieu de pour) ou sémantique (ex. père au lieu de fils). En complément, l’éventuelle corrélation anatomo-clinique (voie ventrale ou dorsale du cortex cérébral) permet de donner des indications pronostiques (Meier et al., 2019), et de définir la conduite à tenir dans le projet thérapeutique. S’il s’agit d’un problème d’accès au lexique interne, l’évaluation précise également si le système sémantique du patient reste organisé (Trauchessec, 2018). La tâche la plus fréquemment proposée dans ces évaluations est celle de la dénomination orale d’images.
Nous posons l’hypothèse que certaines déviations seraient par défaut étiquetées comme sémantiques (ex. tourne-bouchon au lieu de tire-bouchon) alors que l’examen des similitudes morphologiques entre le mot attendu et la réponse produite par le patient pourrait nous éclairer sur les niveaux et mécanismes déficitaires et sur les potentialités de réorganisation fonctionnelle cérébrale. Dans cet article, nous parlerons dans ce cas de paraphasies morphologiques4, par opposition, par exemple, aux paraphasies phonémiques et sémantiques décrites par Nespoulous (1980), pour qualifier les transformations lexicales des aphasiques portant sur des aspects formels, que le mot produit par le patient appartienne ou non au lexique attesté. À ce jour, à notre connaissance, aucun test ne permet de mesurer la relation morphologique entre le mot attendu et le mot produit par le patient. Or la base de données dérivationnelle Démonette peut représenter une ressource intéressante pour les orthophonistes qui ont besoin de sélectionner les items de leurs tests selon des critères morphologiques. En effet, Démonette est une ressource de grande ampleur, qui met à disposition des descriptions riches des unités lexicales, ainsi que les relations dérivationnelles qui les connectent. Dans ce cadre, nous proposons une étude pilote fondée sur un corpus de paraphasies morphologiques, visant à mettre au point une méthode de mesure du niveau de similarité morphologique entre le mot attendu (dans une tâche de dénomination) et la réponse produite par le patient. Cette étude pilote permet (i) de vérifier l’intérêt de l’utilisation envisagée de la base de données Démonette pour créer du matériel d’évaluation ou de traitement orthophonique, et (ii) de tester dans quelle mesure elle pourrait donner lieu à une expérimentation de plus grande ampleur pour identifier des profils de patients en pratique orthophonique.
1. Recueil des données
Dans le cadre du projet DEMONEXT5, nous avons constitué un corpus de 182 couples de mots associant dénomination attendue dans une tâche de dénomination (A) et réponse produite par le patient (P), telle que P est différente de A. La sélection des couples est opérée parmi un ensemble de productions recueillies par M. Tran (voir entre autres Tran, 2018) à partir de données déjà publiées (Bachy-Langedock, 1987 ; Devismes & Sherer, 1998 ; Defives & Sauvé, 1996 ; Deloche et al., 1996, 1997 ; De Partz, 2002 ; Pillon et al., 1991 ; Tran, 2000) ou bien extraites, de façon plus marginale, au cours de séances cliniques en orthophonie. Nous nous sommes limitées aux couples (A, P) dans lesquels A et/ou P est morphologiquement ou syntaxiquement construit. Le nettoyage des données a permis de standardiser l’orthographe des mots, sachant que les productions des patients étaient uniquement orales.
Cette étude s’est déroulée en plusieurs temps pour atteindre nos deux objectifs. Le premier a consisté à rechercher le niveau de similarité morphologique dans des couples de mots (A, P), où P sont des paraphasies construites par la morphologie ou la syntaxe (Tran, 2018). Le résultat de cette première étape permet d’établir la liste des variables pertinentes pour la sélection, dans la base Démonette, des items de tâches de production d’unités lexicales en situation de rééducation (test ou mesures répétées de lignes de base). Le second objectif est d’identifier les types d’écarts entre A et P indiquant que les patients pourraient avoir conservé des connaissances ou des représentations de la construction des mots. Deux questions sont examinées : (a) le patient a-t-il pu avoir recours à une représentation de la structure de A, et/ou de connaissances morphologiques concernant A ? et (b) peut-on mettre en évidence une parenté constructionnelle entre A et P ? À partir des réponses apportées, il est possible d’élaborer une réflexion clinique sur les stratégies thérapeutiques à adopter par les orthophonistes.
Pour des raisons détaillées dans la section 3.2.3, ce jeu de données ne peut pas être considéré comme un corpus quantitativement et qualitativement représentatif. Cependant, les résultats des analyses et les conclusions auxquelles elles conduisent permettent de commenter une démarche méthodologique reproductible6, et de proposer des hypothèses vérifiables à plus grande échelle. La section suivante présente la méthode et les résultats de la mesure de similarité morphologique entre A et P.
2. Comparaison du mot produit (P) avec le mot attendu (A)
Dans chaque paire (A, P) formée par le mot attendu A et la forme produite P, nous avons cherché à évaluer ce qui motivait la formation de P, du point de vue morphologique – la forme et la structure de P présentent-elles des ressemblances avec A ? – et/ou sémantique – le sens construit de P paraphrase-t-il ou évoque-t-il le sens de A ? Nos analyses s’appuient sur les principes de la morphologie lexématique (Aronoff, 1994 ; Fradin, 2003 ; Blevins, 2006 ; entre autres) et de l’approche à base des paradigmes de la dérivation (Bochner, 1993 ; Bonami & Strnadová, 2019 ; Hathout & Namer, 2022 ; etc.), qui sont ceux qui sont instanciés dans la base Démonette. Deux séries de comparaisons sont réalisées : la première s’appuie sur les propriétés morphologiques de P et A (Section 2.1), et l’autre, sur la relation sémantique entre (un composant de) P et (un composant de) A (Section 2.2). Ces traitements indépendants permettent aux résultats obtenus d’être interprétés de façon autonome ou combinée.
Notons avant tout que parmi les formes P de notre sélection, certaines sont enregistrées dans la plupart des dictionnaires de la langue générale (poussoir), d’autres sont attestées, par exemple, en ligne (tapoteur, tuyautière). Cela dit, toutes les formes P construites par la morphologie sont bien formées, c’est-à-dire qu’elles vérifient les contraintes d’application du procédé de formation. Par exemple, le nom masculin essoufflage, construit sur le verbe essouffler n’est (quasiment) pas attesté en ligne, mais sa construction vérifie les mêmes principes de formation que, par exemple, lavage, construit sur le verbe laver : les deux noms désignent l’activité décrite par le verbe de base.
2.1. Comparaison catégorielle et structurelle de A et P
La comparaison des structures de P et A consiste à examiner si A et P (a) relèvent du même mode de construction linguistique (s’agit-il de structures polylexicales ? de mots composés ? dérivés par la morphologie ?), et, si oui, (b) sont formés par le même (type de) procédé (sont-ils dérivés au moyen du même affixe ? de deux exposants correspondant à des procédés dérivationnels voisins ?). Cette comparaison ne tient pas compte de l’existence ou non d’une relation sémantique entre A et P (celle-ci est examinée à la Section 2.2). Elle est effectuée en deux phases : d’abord, les formes A et P sont analysées indépendamment l’une de l’autre (Section 2.1.1), ensuite la comparaison des structures proprement dites est réalisée (Section 2.1.2).
2.1.1. Annotation structurelle de A et P
Concernant l’analyse individuelle de A et P, celle-ci consiste en le codage de la catégorie grammaticale et la description du modèle de construction (dérivationnel ou syntaxique) auquel correspond la forme examinée. L’analyse de la construction de chaque A et P est illustrée dans le Tableau 1. Le codage de la catégorie grammaticale de P est incertain quand le contexte du mot examiné est non disponible alors qu’il serait nécessaire pour la déterminer. C’est ce qu’illustre l’exemple (1), où on ne peut pas déterminer si P =antique (répondant à A = antiquité) est un adjectif ou un nom.
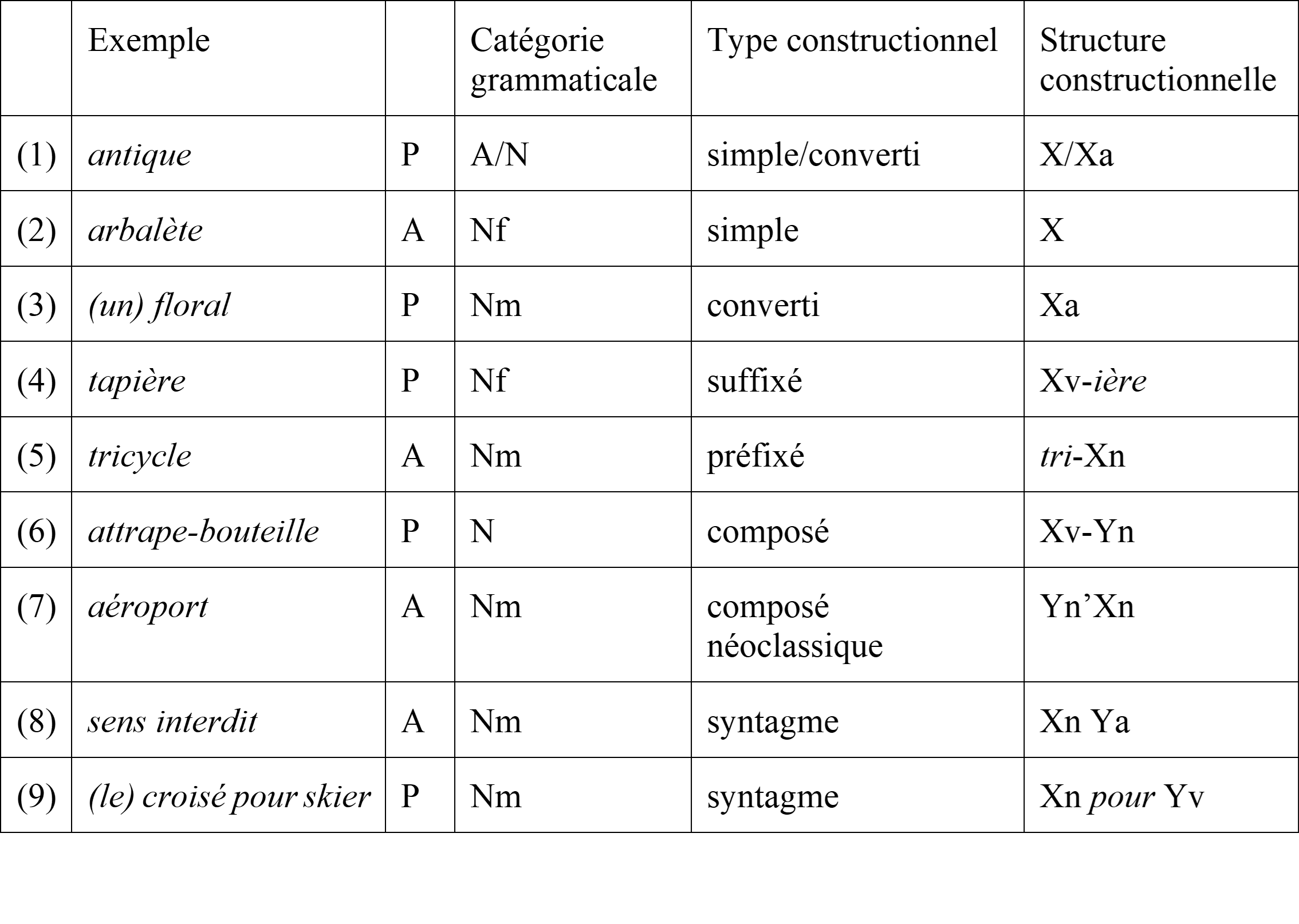 Tableau 1. Structure constructionnelle de A et P
Tableau 1. Structure constructionnelle de A et P
Dans le tableau, la colonne Type constructionnel indique si le mot est simple, construit par la morphologie ou par la syntaxe, et la colonne Structure constructionnelle schématise son mode de construction. La Structure constructionnelle d’un mot simple (Type constructionnel = simple) a pour valeur X où X désigne le radical du mot (ex. 2). Pour les mots construits par dérivation, Type constructionnel vaut suffixé, converti ou préfixé selon le type de procédé en jeu. La valeur de Structure constructionnelle indique la série dérivationnelle7 à laquelle le mot appartient :
– En cas de conversion8, la valeur de ce trait est de la forme Xc où c indique la catégorie grammaticale de la base, et X est le radical commun à la base et au dérivé converti (ex. 3).
– La série dérivationnelle des mots suffixés est de la forme Xc-suf, où suf désigne le suffixe. Comme pour la conversion, Xc est mis pour le radical (X) de la base et sa catégorie (c) (ex. 4). De façon symétrique, la série dérivationnelle des mots préfixés est de la forme pref-Xc, où pref est la valeur du préfixe, et Xc désigne le radical de la base de catégorie c (ex. 5).
Pour les mots construits par composition, Type constructionnel vaut composé ou composé néoclassique selon la nature et/ou l’ordre des composants en jeu. La Structure constructionnelle du mot composé décrit le schéma de composition du mot :
– Un nom ou adjectif composé est considéré comme standard quand chaque composant est réalisé sous la forme d’un radical libre en syntaxe. Sa valeur est de la forme Xc1-Yc2 où c1 et c2 sont, respectivement, les catégories grammaticales des composants X et Y (ex. 6).
– Un nom ou adjectif composé est considéré comme néoclassique quand l’un au moins des composants est représenté sous la forme d’un radical supplétif. Sa valeur est notée sous la forme Yc1Xc2 où c1 et c2 sont les catégories grammaticales des composants. Un composant réalisé par un radical supplétif est signalé par une apostrophe, e.g. Yc1’Xc2 (ex. 7).
Enfin, les séquences polylexicales sont étiquetées par Type constructionnel = syntagme. La valeur de Structure constructionnelle généralise la structure syntaxique de la séquence : il peut s’agir d’une simple combinaison de deux mots (ex. 8), ou d’une structure plus complexe, et inclure une préposition et un déterminant qui spécifie le second mot (ex. 9). Dans tous les cas, la tête syntaxique de la séquence est identifiée par le symbole X.
2.1.2 Comparaison des structures de A et P
En se servant des structures constructionnelles de A et P, on isole et on caractérise le ou les composants (le cas échéant, morphologiques) communs aux deux structures (voir Tableau 2). Ces structures sont regroupées (colonne 3) de manière à faire apparaître, quand elle existe, leur sous-structure commune (colonne 4). Les symboles partagés (Xc1, Yc2, etc.) désignent les constituants lexicaux communs à A et P (ex. 1, 4). Les exposants suffixaux et préfixaux sont généralisés, respectivement, au moyen des valeurs suff et pref. Quand la formation de A et P fait intervenir le même procédé (ex. 2), ou deux variantes du même procédé (comme -eur et ‑euse, cf. ex. 3), alors A et P appartiennent à la même série dérivationnelle, ce que l’on représente en co-indiçant l’exposant abstrait (e.g. suff1 ou pref1). Quand la structure constructionnelle de A ou P comporte une préposition, celle-ci est remplacée par le symbole prep, ex. 6, colonne 3. ; de même, les déterminants sont représentés par det. Quand A ou P est construit et que sa base est elle-même affixée ou comporte une séquence affixoïde9, nous mettons en évidence la structure complexe de cette base (l’exposant présent sur la base est indiqué entre parenthèses), dès lors qu’elle peut servir de point de comparaison supplémentaire. C’est le cas dans l’ex. (5) avec sanglier (qui comporte la séquence ‘ier’ homomorphe au suffixe -ier ayant servi à la formation de cendrier), et également en (8) et en (9) : dans ces deux dernières lignes, l’isolation du préfixe ou du préfixoïde dé‑ (ex. 8) ou per- (ex. 9) met en évidence le radical commun à A et P, e.g. capsule (ex. 8) ou forer (ex. 9). La valeur 0 signale que A et P ne partagent aucune structure (ex. 7).
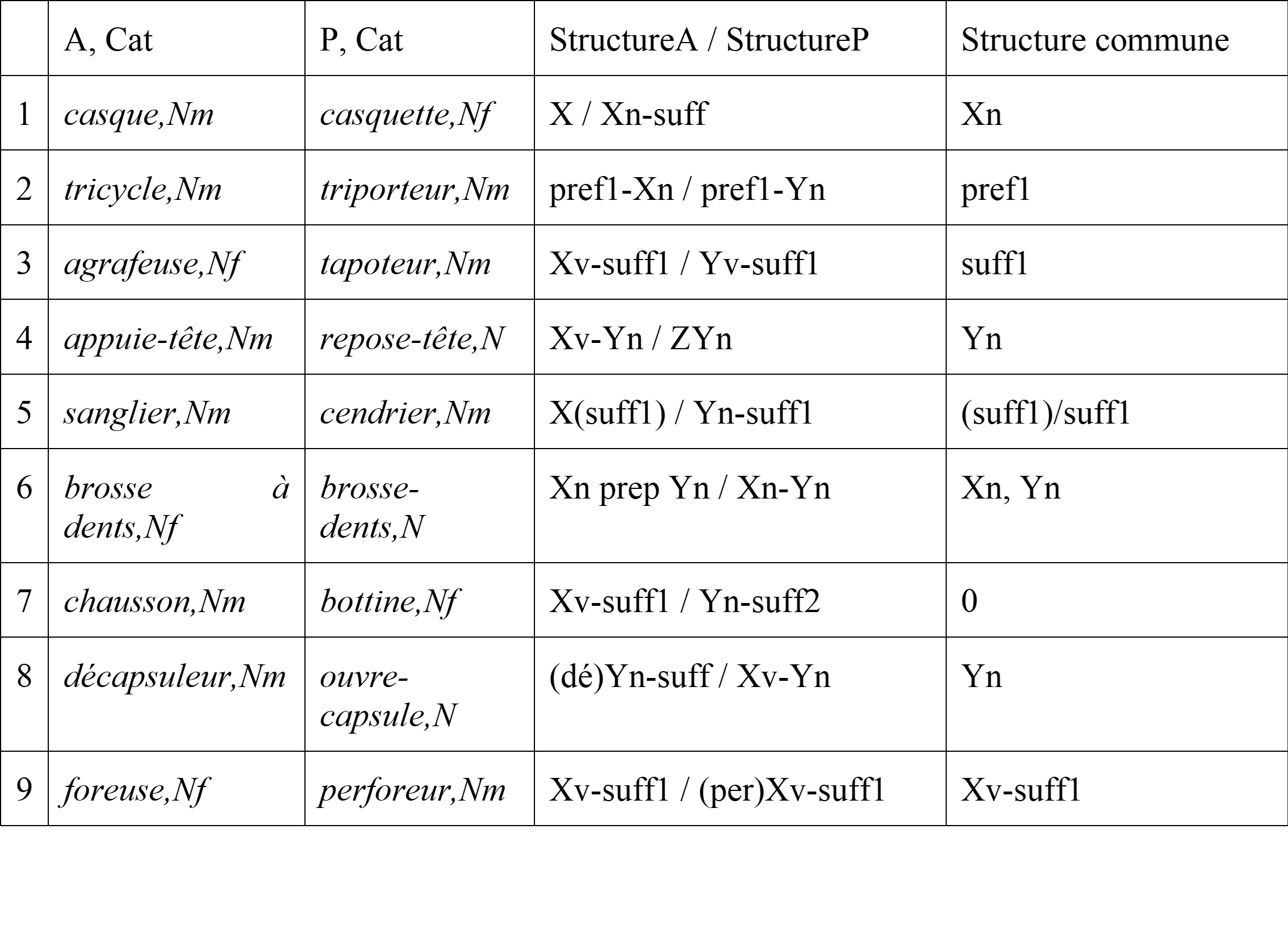 Tableau 2. Comparaison des structures de A et P
Tableau 2. Comparaison des structures de A et P
2.1.3. Bilan quantitatif
Le corpus des mots attendus (A) comporte 44 % dérivés (essentiellement suffixés), 25,3 % mots simples, 24,1 % composés et 6,6 % séquences polylexicales. Les réponses produites par les patients (P) se répartissent comme suit : 51,1 % dérivés (parmi lesquels 91 % de suffixés), 32,9 % composés, 11 % séquences polylexicales et 5 % mots simples. La grande majorité des P sont morphologiquement construits, tous sont bien formés, et plus de la moitié appartient au lexique attesté. On constate donc que, toutes proportions gardées, les formes les plus fréquemment produites le sont par la morphologie (dérivation ou composition) : en majorité, le patient est capable de mobiliser les mécanismes de construction morphologique pour former un mot (en tâche de dénomination d’image), mais sans que cette construction ne soit forcément en lien avec celle du mot attendu, comme nous le détaillons dans la section suivante. Le résultat n’est donc pas forcément efficace d’un point de vue psychométrique et normatif. Enfin, 11 % des couples font partie de la même série dérivationnelle et 32,4 % appartiennent à la même famille : la base (ou un constituant) du mot produit est identique à la base (ou à un constituant) du mot attendu. Pour 43,4 % des couples, la forme produite par le patient semble donc motivée par les propriétés morphologiques du mot attendu : en d’autres termes, 103 couples ne présentent aucune similarité formelle, qu’elle soit morphologique ou lexicale. Nous détaillons et interprétons ces résultats dans la section 3.
2.2. Analyse sémantique
Quel que soit le degré de similarité formelle entre A et P (et notamment pour les couples pour lesquels P n’a pas de constituant commun avec A), le versant sémantique de notre travail de comparaison consiste à examiner P et A du point de vue de leur relation lexicale sémantique. P paraphrase-t-il A, dont il serait un synonyme ? L’un des deux mots est-il l’hyponyme de l’autre ? Existe-t-il entre les deux mots une relation de partie à tout ? P décrit-il la fonction typique du référent de A ? Son mode opératoire ? Son agent ou instrument ?
Prenant appui sur l’analyse structurelle de A et P présentée à la section 2.1.1 et illustrée dans le Tableau 1, l’étude sémantique, étendue aux composants de A et P, a permis de montrer que dans 16 % des couples P n’a sémantiquement rien à voir avec A, indépendamment de l’existence d’un lien formel entre P et A. Nous avons analysé la relation sémantique entre (un constituant morphologique ou syntaxique de) P et (un constituant morphologique ou syntaxique de) A. Par exemple, dans (A, P) = (agrafeuse, tapoteur), la base verbale tapoter de tapoteurNm définit le mode opératoire de certaines agrafeuses (par exemple, les agrafeuses murales), ce qui nous a conduits à nommer mode_opÉratoire la relation entre l’activité dénotée par la base verbale tapoter de P (tapoteur) et le nom agrafeuse (A).
Suivant ce principe, nous avons identifié 12 relations mettant en jeu P (ou l’un de ses composants) et A (ou l’un de ses composants) ; 34,6 % des P (e.g. aspiration, chauffe-eau, attache-gosier) font référence soit à la FONCTION, soit au mode_opÉratoire de ce qui est dénoté par A (aspirateur, bouilloire, muselière) : l’aspiration, c’est la fonction de l’aspirateur, chauffer l’eau, c’est celle de la bouilloire, et attacher sous le gosier, c’est la mode opératoire de la muselière ; 14,8 % des couples entretiennent une relation d’inclusion (HYPONYMIE, HYPÉRONYMIE, COHYPONYMIE), comme cafetière et bouilloire ; 14,2 % sont synonymes (pose-tête et appuie-tête). Pour 19,2 % des couples (A, P) il n’a pas été possible d’identifier d’indice sémantique, e.g. poussette et bourgeon. Parmi les autres relations sémantiques entre P et A, on trouve des cas où (i) P (porte-plume, chausse-chaussure) désigne ce qui contient ou est contenu dans ce à quoi renvoie A (plumier, chausse-pied) : on trouve un porte-plume dans un plumier, la chaussure sert à contenir le pied ; (ii) P (tuyautière) et A (gouttière) incluent une relation de méronymie : le tuyau est une partie de la gouttière ; (iii) P (rougette) fait référence à une propriété typique de ce que désigne A (coquelicot) : un coquelicot est rouge. Exceptionnellement, la relation entre P et A met en jeu une combinaison de plusieurs prédicats (suivant le sens qu’en donne traditionnellement la sémantique lexicale). Par exemple, pendentif est lié à boucle d’oreille par une relation de cohyponymie (ce sont des bijoux), et par une relation fonctionnelle (« pendre » est la fonction de certaines boucles d’oreille).
Notons que cette étude est une première tentative d’annotation sémantique des relations entre P et A, et que le codage de ces prédicats doit encore être affiné, en particulier de manière à distinguer clairement ce qui relève des hiérarchies lexicales (hyponymie, méronymie, synonymie) et ce qui relève des relations entre une situation et ses participants. Il pourrait en effet être intéressant d’examiner d’autres relations lexicales comme la similarité des référents (e.g. cuiller à chaussure proposé pour chausse-pied, ou vase-œuf proposé pour coquetier), en lien également avec les compétences neuro-visuelles du patient.
3. Interprétation des résultats
Nous examinons à présent les résultats ci-dessus d’un point de vue clinique : nous cherchons à en déterminer l’impact dans la compréhension des processus impliqués chez le patient, et les conséquences possibles sur le plan thérapeutique.
3.1. Intérêt des listes contrôlées
Les résultats de la section 2 montrent que (i) dans 43,4 % des cas, P et A sont morphologiquement reliés, que 84 % de ces relations sont également motivées sémantiquement, et que (ii) pour 87 % des couples (A, P) sans relation ni morphologique, ni syntaxique, le patient a recours, avec P, à une approximation sémantique de A. Cela nous indique qu’en orthophonie, ce type d’analyse peut compléter les points de vue phonologiques et sémantiques habituellement adoptés pour l’analyse des paraphasies.
Ces constats confirment également selon nous la nécessité d’un passage à l’échelle à partir de listes de mots contrôlés d’un point de vue morphologique. En effet, la méthode d’analyse présentée permet de mettre en évidence l’existence d’une relation formelle et sémantique entre A et P, et de mesurer le cas échéant les propriétés morphologiques de cette relation. Or on sait que l’analyse des niveaux d’atteinte lexico-sémantiques dans le cadre de l’aphasie s’effectue à partir de listes de données statistiquement valides (Badecker & Caramazza, 2001 ; Python & Sainson, 2022). Par conséquent, si l’orthophoniste dispose de listes contrôlées, on peut estimer que ces analyses seront pertinentes, car correctement ciblées, et que la stabilité des tests conçus de cette façon sera optimale. Enfin, si le large panel des résultats obtenus avec notre jeu de données est reproduit à grande échelle, cela pourrait confirmer qu’il existe cliniquement une grande variété de profils différents d’aphasiques (Joanette et al., 2018).
3.2. Relation morphologique entre A et P
L’interprétation clinique des relations entre A et P nous sert à déterminer dans quelle mesure le patient a conservé une représentation morphologique du mot attendu, s’il peut accéder à cette représentation et s’il y a recours. Deux cas de figure sont examinés : A et P sont morphologiquement disjoints mais peuvent être structurellement comparables (Section 3.2.1) ou ils sont morphologiquement apparentés (Section 3.2.2). Les conclusions nous conduisent (Section 3.2.3) à un ensemble d’hypothèses sur les modes d’intervention orthophoniques auprès de personnes avec aphasie, et à quelques préconisations sur les choix de sélection à effectuer dans la base de données Démonette pour obtenir une liste contrôlée d’items à utiliser lors de ces interventions.
3.2.1. A et P n’ont pas de relation morphologique
Dans plus de la moitié des couples (56,6 %), A et P ne sont pas morphologiquement reliés (ni de la même famille, ni dans la même série). Dans 33 % de ces couples, P est un composé Xv‑Yn (ex. : lave-vaisselle pour éponge), laissant penser que cette construction est la plus facilement accessible pour les patients aphasiques dans la tâche de dénomination d’images d’objets concrets. Dans 13 % des autres couples (A, P), P est un nom masculin déverbal d’instrument suffixé en -eur, alors que 45 % des A sont des mots simples (ex. mélangeur est proposé pour fouet). On observe que cette construction morphologique est sémantiquement motivée : dans 46,6 % des cas, P exprime (in)directement la FONCTION du référent de A (ex. le fouet [de cuisine] sert à mélanger). Plus généralement, lorsque le patient ne mobilise aucune connaissance morphologique liée au mot attendu, il a recours dans 85,6 % des cas à une autre stratégie de dénomination, faisant intervenir la voie d’accès sémantique (par exemple, le patient produit ramasse-poussière pour aspirateur). Le reste du temps (c’est-à-dire dans 14,5 % des cas), P n’est ni morphologiquement apparentée à A, ni sémantiquement motivée : cette déconnection complète entre A et P signifie que le patient n’a accès à aucune des connaissances lexicales10 requises (par exemple il produit pince à écrire pour casse-noix, ou chevillères pour bigoudis).
Dans les couples sans parenté dérivationnelle (ni famille ni série), on s’intéresse ensuite aux types de procédés (affixation ou composition) formant A et P : on observe que le patient fait appel dans 25 % des cas à des connaissances morphologiques pour proposer un mot qui « imite » la structure constructionnelle de A. L’imitation consiste à reproduire le même type de procédé (suffixation, préfixation), mettant en jeu des exposants différents mais concurrents (c’est-à-dire produisant le même type sémantique de dérivé, voir e.g. Aronoff [2016] ; Rainer et al. [2019] sur la concurrence affixale) appliqués au(x) même type(s) catégoriel(s) de base(s). Par opposition à l’analogie proportionnelle (Arndt-Lappe, 2015 ; Dal, 2008, entre autres) qui explique la formation de nouveaux mots complétant une série préexistante, comme femme-grenouille à partir de homme-grenouille, ce mimétisme peut être qualifié d’analogie structurelle. Il s’observe surtout avec les dérivés et les composés sur base verbale. En effet, dans 16,5 % des cas, P est un nom déverbal formé au moyen d’un concurrent dérivationnel du procédé de dérivation de A : par exemple, dans (A, P) = (bouilloire, chaufferette), les deux noms déverbaux sont dérivés au moyen de deux procédés rivaux, puisque -oire et -ette servent tous les deux à former (entre autres) des noms d’instruments. Dans 9 % des cas, enfin, P et A sont tous les deux des composés de type V+N, comme chausse-pied et enfile-chaussure, ou essuie-glace et lave-vitre.
Ces cas de mimétisme montrent que le patient a conservé la structure morphologique du mot attendu, et qu’il a pu en activer une représentation morphologique partielle, à défaut de pouvoir sélectionner les composants appropriés. À ce sujet, Semenza et al. (2011) ont observé que ce type de substitutions semble plus prégnant dans les cas d’aphasies anomiques. Enfin, l’absence de similitude structurelle dans notre jeu de données dans les cas où A est préfixé concorde avec les résultats de Ciaccio et al. (2020), pour qui les mots préfixés semblent plus difficiles à récupérer que les mots suffixés.
3.2.2. A et P sont morphologiquement reliés
Lorsque A et P entretiennent une relation morphologique (43,3 % des cas), ils appartiennent dans 74,7 % à la même famille (A =aspirateur, P =aspiration), et dans 25,3 % ce sont deux membres de la même série dérivationnelle (A =balançoire, P =poussoir). Il est alors raisonnable de penser que le patient a pu récupérer une information morphologique partielle appartenant bien au mot attendu et qui lui sert dans l’acte de dénomination.
On a vu qu’en majorité, A et P sont des mots suffixés ou composés. On observe que si A est construit par dérivation, alors P l’est aussi dans 67 % des cas. Quand A est un composé, P l’est aussi, mais dans 50 % des cas seulement. Enfin, la proportion globale des mots simples passe de 26 % (A) à 6 % (P), ce qui contredit partiellement les observations de Semenza et Mondini (2015), et notamment le compound effect selon lequel les patients remplaceraient des mots simples par des mots simples et des mots composés par des mots composés.
3.3. Perspectives pour la pratique de l’orthophonie
Les résultats présentés ci-dessus doivent être pris avec précaution. Rappelons en effet que les données examinées ne sont que des exemples de comportements possibles des patients (voir Section 1). Les hypothèses émises dans cet article devront être vérifiées par des études de plus grande ampleur qui tiennent compte des caractéristiques des patients (âge, niveau socio-culturel), et de l’aphasie (données anatomophysiologiques telles que la taille et la localisation de la lésion, l’hémisphère impliqué, les déficits associés…). Enfin nous n’avons pas eu accès à l’ensemble de l’énoncé, ni ne connaissons réellement la situation d’énonciation, alors que ces informations complémentaires permettent d’affiner les hypothèses et de mieux orienter l’analyse des procédures.
Cela étant, le Tableau 3 recense les principaux niveaux de similarité morphologique entre A et P dans notre jeu de données. La colonne 2 illustre chaque situation. Les colonnes 3 et 4 indiquent, respectivement, la nature de la parenté morphologique entre P et A (0 si A et P sont morphologiquement disjoints) et le type de procédé commun à A et P (la valeur de 0 indique qu’ils n’en partagent aucun). Les types de couples (A, P) sont classés suivant la proximité constructionnelle décroissante entre P et A : dans les lignes 1 à 6, A et P sont de la même famille ou appartiennent à la même série (ou, à défaut, à des variantes d’une même série, ou des séries issues de procédés concurrents), dans les lignes 7 et 8, la structure formelle de P imite celle de A, dans les lignes 9 et 10, P et A partagent un composant mais ont des structures différentes, et enfin, en 11 et 12, P et A n’ont ni composant ni structure commune.
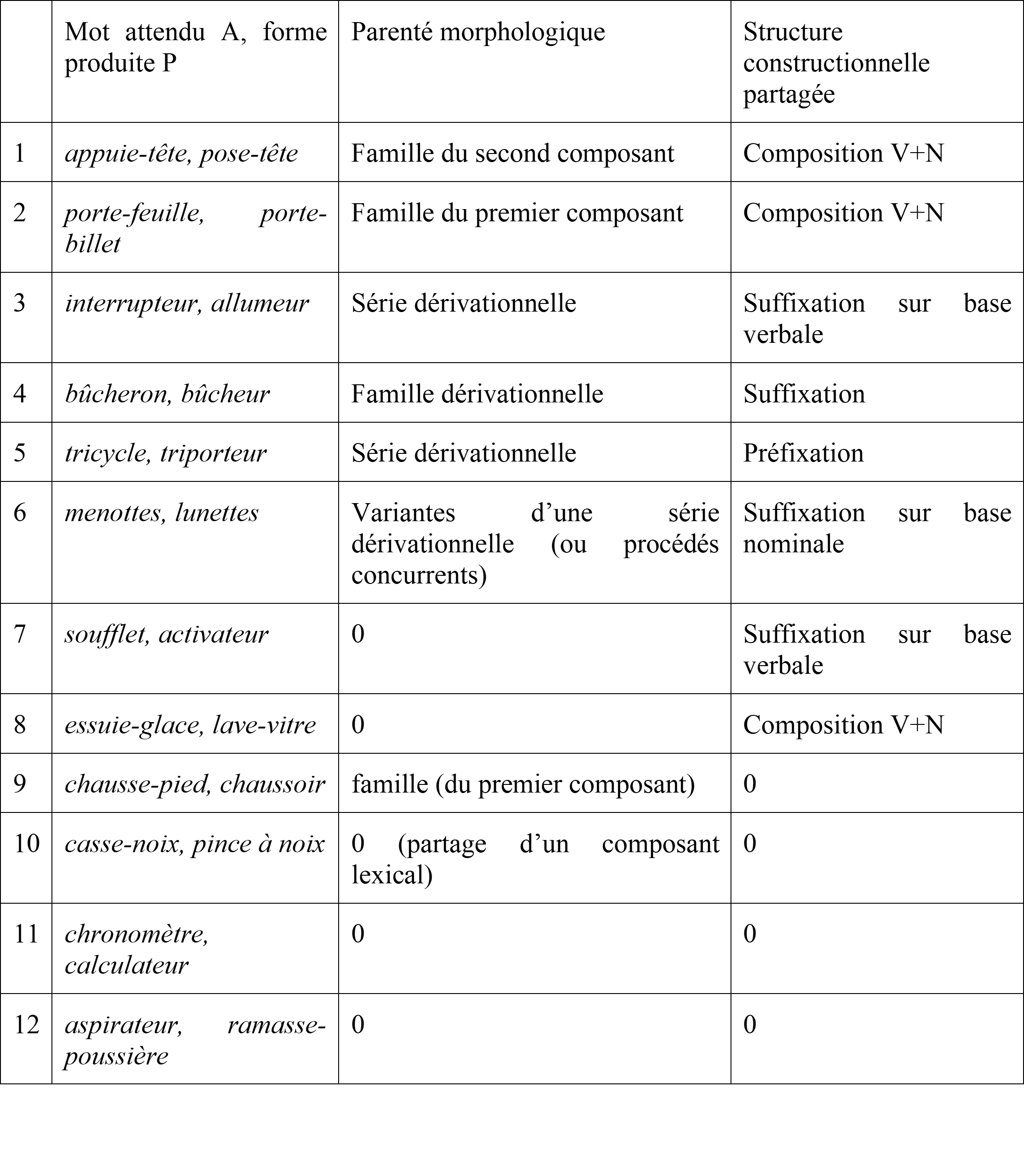 Tableau 3. Similarité morphologique décroissante entre A et P
Tableau 3. Similarité morphologique décroissante entre A et P
De ces divers cas de figure, et selon les proportions majoritairement mises en évidence dans les évaluations, découlent des hypothèses cliniques et des stratégies à proposer au patient, une fois les évaluations complétées par une exploration des systèmes fonctionnels liés à l’anomie.
(a) Quand P et A sont dans la même famille, ou appartiennent à la même série, et possèdent la même structure constructionnelle (ex. 1 à 5), cela semble indiquer que le patient a pu avoir recours à une représentation et à des connaissances morphologiques du mot attendu, qui sont par conséquent préservées et accessibles, ce qui confirme les observations de Kavé et al. (2012) concernant les atteintes sémantiques sévères. Le plan thérapeutique concernant l’accès au lexique pourrait privilégier des tâches liées au système sémantique lui-même (comme la reconstitution de champs sémantiques, ou l’association de mots).
(b) Si les connaissances du patient sont préservées partiellement mais ne lui permettent pas de produire une forme appartenant à la famille ou à la série du mot attendu (ex. 6 à 8), ou si au contraire, A et P partagent un composant mais résultent de procédés distincts (ex. 9, 10), alors le plan thérapeutique pourrait viser une restauration de ces compétences morphologiques partiellement conservées.
(c) Si enfin, aucun lien morphologique entre A et P n’est observé (ex. 11, 12) alors un travail sur les compétences morphologiques du patient ne semble pas utile, au moins en première intention : l’accès au lexique pourrait être renforcé de façon plus pertinente grâce à la reconstitution d’indices sémantiques, par exemple la semantic feature analysis (Maddy et al., 2014).
La sélection de mots dans la base de données Démonette, à des fins d’évaluation ou d’entraînement, devrait par conséquent inclure des structures affixées, et notamment préfixées (qui figurent très peu dans les tests actuels [Rigollet, 2022]), afin de vérifier si le système de représentation morphologique lexical est atteint ou non. De plus, les listes devraient également inclure des mots simples à des fins de comparaison dans la vitesse de traitement, et des structures composées pour confirmer la fréquence inhabituelle des structures de type V+N pour pallier l’anomie chez les patients avec aphasie vasculaire.
4. Conclusion
Nous avons mis au point une méthode d’analyse des couples (mot attendu [A], paraphasie à structure lexicale complexe [P]) chez les patients avec aphasie, permettant d’établir s’il existait une similarité entre A et P, et si oui de quel ordre. Nous avons montré que la majorité des réponses des patients étaient construites morphologiquement et bien formées. Ce sont principalement des composés V+N ou des noms déverbaux suffixés. Nous avons vu aussi que dans plus de la moitié des cas, A et P ne sont pas reliés morphologiquement. Lorsqu’un lien morphologique a pu être observé, A et P appartiennent dans plus de trois quarts des cas à la même famille morphologique.
L’approche proposée comporte plusieurs phases d’analyse morphologique qui pourraient être reproduites lors de l’intervention orthophonique afin de compléter la compréhension des troubles du patient par une analyse des indicateurs morphologiques présents. Les travaux récents en aphasiologie, notamment ceux en lien avec le modèle en double voie, ont en effet montré que les mots sont stockés dans notre système sémantique grâce à plusieurs indicateurs morphologiques et sémantiques (Yablonski, 2021), et sont récupérés, même lorsqu’ils sont complexes, en fonction de leur fréquence (Badecker & Caramazza, 2001), soit dans leur forme complète, soit via une procédure de décomposition (Clahsen et al., 2003). Dans une perspective de mise au point de tests d’évaluation ou de construction de lignes de base, il semble donc intéressant de pouvoir disposer de listes de mots contrôlées permettant d’affiner l’interprétation des résultats et l’état des représentations morphologiques des mots chez les patients avec aphasie. La base de données Démonette, fondée sur de relations dérivationnelles entre les mots, permet de faciliter pour les orthophonistes la tâche de constituer ces listes contrôlées.
Notre analyse propose de regrouper les patients selon le type de décalage morphologique en production orale entre le mot attendu A et la réponse produite P. Sur la base de ces constats, nous avons identifié trois jalons principaux dans le continuum entre quasi-identité formelle entre P et A et distance maximale, qui permettent d’envisager trois profils de patients que nous avons décrits dans la section 3.2.3 : (a) représentation morphologique conservée du mot attendu, (b) mimétisme constructionnel et (c) aucun point commun avec le mot attendu. Par ailleurs, d’un point de vue sémantique, c’est la fonction de l’objet qui figure sur l’image à dénommer qui semble être l’indicateur sémantique le plus accessible et utilisé par le patient.
Sur le plan de la stratégie thérapeutique, et sous réserve que ces hypothèses soient confirmées par une étude de plus grande ampleur, l’orthophoniste pourrait tout d’abord tenter d’identifier, au travers de l’analyse des réponses apportées par le patient, l’état des représentations morphologiques et le degré de similarité morphologique avec le mot attendu. Selon les cas, et en fonction des objectifs de restauration ou de compensation établis en accord avec le patient à la suite du bilan orthophonique, le plan thérapeutique visant à faciliter l’accès au mot envisagera de restructurer les connaissances morphologiques avant de pouvoir les utiliser, ou bien visera l’utilisation préférentielle des indices sémantiques.
Plus globalement, il semble important de tenir compte du type et de la structure constructionnelle des mots attendus pour l’édition des tests et des lignes de base en orthophonie. La base de données Démonette ouvre des perspectives en ce sens pour les professionnels de terrain et les praticiens-chercheurs. En effet cette ressource dérivationnelle est tout à fait appropriée pour la construction des listes de travail et/ou de test : son outil de recherche permet notamment d’extraire de façon sélective des ensembles de mots choisis suivant leur mode de formation.